目前正在研究如何在浏览器中画图:直线,椭圆等等。在Google上搜了一把,发现了一个canvas的标签。这个标签可以完成大多数画图的任务。不过很不幸,IE不支持这个标签。不知道在IE下画图有什么快速的好办法,如果谁知道,麻烦告诉我。
Now, I study how to draw graphics in browser. I search by Google, and find canvas tag. This tag can finish much draw task. But unfortunately, IE does not support this tag. I do not know there are some quickly methods to draw under IE. If someone know, tell me.
2006-12-31
2006-12-27
2006-12-25
Problem 最小集合元素和
给定两个集合X,Y,每个都有n个元素。现在定义集合X+Y = {x+y | x in X and y in Y}现在问用什么方法可以最快的给X+Y排序。
这个问题还有一个描述就是,给定两个从小到大排好序的集合X,Y,每个都有n个元素。现在要找X+Y的最小的k个元素,问最快的方法是什么。
有人说后一个问题有O(klogk)复杂度的解决方案,正在探索中。O(n^2)的算法是显然的。
这个问题还有一个描述就是,给定两个从小到大排好序的集合X,Y,每个都有n个元素。现在要找X+Y的最小的k个元素,问最快的方法是什么。
有人说后一个问题有O(klogk)复杂度的解决方案,正在探索中。O(n^2)的算法是显然的。




2006-12-23
An antiarithmetic permutation
给定一个正整数n,计算出一组{0,1,2,...,n}的排列,使得这个排列的任何子序列都不能形成等差数列,比如 n=4时,(2, 0, 1, 4, 3)符合要求,但是n=6时,(0, 5, 4, 3, 1, 2)不符合要求,因为(5,4,3)(5,3,1)都是等差数列。
这个题目可以有一个nlgn的算法,首先我们注意到{偶数,奇数,奇数},{偶数,偶数,奇数}是不可能形成等差数列的,那么给定一个n,然后将序列分成2部分:
{偶数列} {奇数列}
可以看出任何子序列,如果既有元素属于偶数列,又有元素属于奇数列,是不可能构成等差数列的。下面我们只要保证偶数列和奇数列各自的子序列不会形成等差数列。这很容易,我们只需要将偶数列的每个数除以2,这是又形成了一个{0,1,2,[n/2]}的序列,可以用前面的方法把这个也分成奇数偶数列。同理,对奇数列只需要减1除以2,也可以用前面的方法排列,如此递归下去,就可以形成满足要求的排列。
这个题目可以有一个nlgn的算法,首先我们注意到{偶数,奇数,奇数},{偶数,偶数,奇数}是不可能形成等差数列的,那么给定一个n,然后将序列分成2部分:
{偶数列} {奇数列}
可以看出任何子序列,如果既有元素属于偶数列,又有元素属于奇数列,是不可能构成等差数列的。下面我们只要保证偶数列和奇数列各自的子序列不会形成等差数列。这很容易,我们只需要将偶数列的每个数除以2,这是又形成了一个{0,1,2,[n/2]}的序列,可以用前面的方法把这个也分成奇数偶数列。同理,对奇数列只需要减1除以2,也可以用前面的方法排列,如此递归下去,就可以形成满足要求的排列。
2006-12-22
高精度计算问题
在科学计算中常常需要进行高精度计算,这时计算机提供的int,double型精度不够,我们需要无限精度的数据结构来解决这个问题,为此,网上有很多相应的库。
1. CLN - Class Library for Numbers
2. NTL: A Library for doing Number Theory
3. GNU Multiple Precision Arithmetic Library

1. CLN - Class Library for Numbers
2. NTL: A Library for doing Number Theory
3. GNU Multiple Precision Arithmetic Library
2006-12-21
计算机程序设计艺术:学习
Knuth的这本著作一向被人放在书架上作为一种炫耀的资本,好像有了这本书,就能说明自己已经比较牛了。我一直也是这样,但决定从今天起,认真攻读它的第三卷:排序和查找。我相信,硬着头皮读下来,一定会对我有很大的帮助。
Donald Knuth(高德纳)
转自http://www.tianyablog.com/
Donald Knuth自传的开头这样写道:“Donald Knuth真的只是一个人么?”作为世界顶级计算机科学家之一,Knuth教授已经完成了编译程序、属性文法和运算法则的前沿研究,并编著完成了已在程序设计领域中具有权威标准和参考价值的书目的前三卷。在完成该项工作之余,Knuth还用了十年时间发明了两个数字排版系统,并编写了六本著作对其做了详尽的解释说明,现在,这两个系统已经被广泛地运用于全世界的数学刊物的排版中。随后,Knuth又发明了文件程序设计的两种语言,以及“文章性程式语言”相关的方法论。
到目前为止,Knuth已经出版发行了17部书籍,一百五十余篇论文,包括了巴比伦算法、圣经、字母“s”的历史等多方面的内容。作为一名数学家, Knuth曾开创了几门新的课程,为纯计算数学做出了很大贡献。他所获得的奖项和荣誉数不胜数,其中最值得注目的有1974年美国计算机协会图灵奖 (ACM Turing Award),1979年美国前总统卡特授予的科学金奖(Medal of Science)以及1996年11月由于发明先进技术荣获的极受尊重的京都奖(Kyoto Prize)。在不多的业余时间里,Knuth不仅写小说,还是一个音乐家、作曲家、管风琴设计师。
是Knuth独特的审美感决定了他兴趣广泛、富有多方面造诣的特点,Knuth传奇般的生产力也是源于这一点。对于Knuth来说,衡量一个计算机程序是否完整的标准不仅仅在于它是否能够运行,他认为一个计算机程序应该是雅致的、甚至可以说是美的。计算机程序设计应该是一门艺术,一个算法应该像一段音乐,而一个好的程序应该如一部文学作品一般。
早期经历
Knuth,1938年1月10日生于美国威斯康星州密尔沃基市。他在模式方面辨别和熟练操作的能力在八年级的时候开始显现出来。当时,当地的一家糖果制造商举办了一项比赛,比赛要求选手用其品牌“Ziegler's Giant Bar”中的字母组成新的单词,规定时间内组成单词数量最多者获胜。Knuth参加了比赛,并以单词总数4500余个远远超过了裁判的2500个的标准,轻松赢得头奖。赛后,Knuth说道,如果自己当初想到回答时用些省略符号的话,还能写出更多。这次比赛Knuth为学校赢得了一台电视机,还为每个同学赢得了一根糖果棒。
Knuth多产的出版事业开始于他的高中时代,当时他的科技设计被Westinghouse Science Talent Search 光荣提及。他的“Potzebie System of Weights and Measures ”的基础章节被登在“Mad”杂志第26号,“Power”的基础章节被叫作“whatmeworry”。“Mad”的编辑认识到了年轻的Donald著作的重要性,以25美元买下了他的文章,并刊登在了其1957年6月的期刊上。
高中的时候,Knuth对数学并没多大兴趣,而是把主要精力放在主修的课程:听音乐和作曲上。他在高中的乐队里吹萨克斯、大号时,曾把 Dragnet、 Howdy Doody Time 和 Brylcream的主题曲联成一段新的音乐。这位著名的科学家在近期评论自己的早期作品时承认:“对于版权,我一无所知。”
虽然Knuth的等级平均分是学校历史上最高的,但是他和他的指导老师还是对他能否成功学习大学数学持怀疑态度。Knuth说在他高中阶段和大学早期一直有一种自卑感,这个问题一度是他的一个障碍。作为一个大学新生,Knuth没有对于失败的恐惧,他花了许多时间攻克额外的数学难题,几个月后,他在这方面的能力已经远远超过了其他同学。
高等教育和早期的计算机工作
当Knuth在Case科学院(现在的Case Western Reserve)获得物理奖学金时,梦想成为一个音乐家的计划改变了。Knuth回去继续研究数学是在大二,当时一个爱出难题的教授提出了一个特殊的问题,并说哪个学生能解决这个问题就立刻记成绩“A”。Knuth跟大多数同学一样,也认为那是道解不出来的题目,直到有一天,他错过了公共汽车,只能步行去看一个演出,Knuth利用路上这点空闲时间决定尝试一下。那阵子他运气真的是非常好,不仅问题很快就解开了,得到了“A”,还成功地经常逃课。虽然 Knuth也承认,逃课让他有负罪感,但是很明显,他完全有能力补上落下的功课,接下来的一学年,他的离散数学就又得了个“A”,而且还获得了给自己不能参加的课程评定论文等级的工作机会。
1956年,作为Case的新生,Knuth第一次接触到了计算机,那是一台IBM 650。Knuth说直到一年后,女孩才进入了他的生活。这又是计算机科学界一直以来亏欠科学家们的一个事例之一。
Knuth熬夜读IBM 650的说明手册,自学基本的程序设计。那时,在高等计算机语言发明之前,程序编写只能用第二代或是汇编语言。这个工作既耗时又困难,因为指令必须根据每台机器特定的构造编写,而实际上指令只须一步就可从二进制0、1系列转存到计算机硬盘上。Knuth说,有了第一次使用650的经历,他便肯定自己能编写出比说明手册上介绍的更好的程序。
Knuth很快便开始“闲逛”,编写可以执行数学函数的程序。他的第一个程序是把数字转化为素数,第三个是做井字游戏(或者说是让计算机在改正每次输的错误的过程来学会玩井字游戏)。作为学校篮球队的经理,Knuth编写了一个根据不同成绩标准评定每个运动员对球队贡献等级的程序,他的努力赢来了那些认为这样做有助于球队赢得同盟冠军的教练的好评(虽然,无庸质疑,不是每一个运动员都这样认为)。Knuth的成就成了新闻周刊的标志,他和教练、计算机的照片也被刊登在IBM650后来的说明手册上。
1960年,Knuth从Case毕业时享有着最高荣誉,在由全体教员参加的选举上,他因其公认的出众成就获得了硕士学位。1963年,Knuth 回到加利福尼亚理工学院攻取了数学博士学位,之后成为了该院的数学教授。在加利福尼亚理工学院任教期间,Knuth作为Burroughs 公司的顾问继续从事软件开发工作。1968年,他加入了斯坦福大学,九年后坐上了该校计算机科学学科的第一把交椅。1993年,Knuth成为斯坦福大学 “the Art of Computer Programming”(计算机程序设计艺术)的荣誉退休教授。
早期成就和计算机程序设计艺术的开端
1962年,Knuth还是个研究生的时候就开始了他计算机程序的工作。那时,他已经开始了个人咨询,为不同的机器编写编译程序。编译程序是一种翻译原始或高级语言和对象或二进制机器语言的中间语言。在不知道众多软件公司正高额寻求成百上千的编辑者的情况下,Knuth编写了一个程序,赚得5000 美元,他的名字立刻响誉了整个行业。世界上一流的出版社Addison-Wesley找到Knuth,请他写一本关于编译程序的书。到1966年, Knuth已经发表了3000页的手写设计草图,并且发明了一种综合方法,用于分析或决定结构翻译所客观需要的文法规则。最近,关于他的那第一部著作, Knuth自己这样评述:“用三年半的时间写第一章可并不是件好事。”
当Knuth的出版商计算出他的那3000页的笔迹打印成文章大约需要2000页时,大家才发现这实际上是一项多么大的工程。Knuth决定将它详述,成为一部更大的关于程序设计科学的纵览,共分为七个部分。一部巨著就这样——诞生了。《计算机程序设计艺术》,至今仍是各程序类图书书架上标志性的书籍。微软首席执行官比尔•盖茨在1995年接受一次采访时说,“如果你认为你是一名真正优秀的程序员,就去读第一卷,确定可以解决其中所有的问题。”值得注意的是,盖茨本人读这本书时用去了几个月的时间,并同时进行了难以置信的训练。盖茨还说:“如果你能读懂整套书的话,请给我发一份你的简历。”
依Knuth本人所讲,《计算机程序设计艺术》是他毕生最重要的事业,其目的是“组织和总结所知道的计算机方法的相关知识,并打下坚实的数学、历史基础”。Knuth撰写的前三卷被翻译成多种语言,到1976年为止,已卖出超过一百万册。他目前正全神贯注地编写第四卷,他期望第四卷的篇幅约为 2000页,并分为三个独立的章节。为了完成丛书的其余部分,Knuth现在进入了一种引退的状态,全身心地投入这项工作。Knuth说,一般说来,他更喜欢在一段时间内集中精神完成一项工作,正像他自己在书中提出的:按“一批”的模式。
Knuth从他主要的工作计划中拿出了十年,即从1976年起,致力于对数字排版的研究,设计了著名的文件准备TeX系统,字体生成程序METAFONT。这项工作带来的值得注意的副产品是用于结构文件和“文章性程式语言”附随方法论的WEB和CWEB语言。
现在,Knuth和他的妻子Jill,两个孩子John 和Jennifer一起,住在斯坦福大学校园里。他继续着《计算机程序设计艺术》第四卷的编写工作。虽然说Knuth是全身心的投入这一项工作,但他还是能挤出时间研究MMIX的设计,那是一台64位RISC(精简指令集计算机)。而他的业余爱好仍然是音乐,还一直邀请那些能够即兴演奏四手联弹钢琴曲的人们给他留下便条,以便安排一些活动。
成就简要回顾
编译程序
编译程序能够实现高级语言和二进制机器语言之间的翻译。二十世纪六十年代初期,Knuth教授致力于这方面的研究,虽然现代的软件已经可以使其变的简单一些,但编写编译程序仍被认为是一项极为困难的工作。Knuth教授在这方面最著名的成就是LR(k)分析的研究,那是一个能使确定一串字符文法规则的过程更加顺畅的值得注目的方法。
属性文法
在编译程序的工作之后,Knuth教授走上了形式上定义程序语言意义
2006-12-20
Graph and Pagerank
Graph和Pagerank目前在检索里有了越来越广泛的应用。
首先,Graph已经成为特征表示的一个重要模型,现在很流行用Graph表示一篇文章,相对于传统的关键词集合,这种表示已经大大的包含了文本本来的信息。
而pagerank算法则是Grpah中排名的一个重要算法,比如,自动摘要中,想找出一个文章中最重要的一句话,那么可以把文章中所有的话看作一个个节点,从而构建一个图,然后用pagerank算法对每句话的重要性排名。
graph表示中的主要问题就是
1.如何定义顶点
2.如何定义边
3.如何定义边的权重
而pagerank的作用就是给每个顶点一个排名
看来pagerank,以及Page那句网络是个图的想法,对计算机网络的影响还是很深远
现在基本的思想就是
1.任何事物都可以用图表示
2.任何事物的排名都可以用pagerank算法
首先,Graph已经成为特征表示的一个重要模型,现在很流行用Graph表示一篇文章,相对于传统的关键词集合,这种表示已经大大的包含了文本本来的信息。
而pagerank算法则是Grpah中排名的一个重要算法,比如,自动摘要中,想找出一个文章中最重要的一句话,那么可以把文章中所有的话看作一个个节点,从而构建一个图,然后用pagerank算法对每句话的重要性排名。
graph表示中的主要问题就是
1.如何定义顶点
2.如何定义边
3.如何定义边的权重
而pagerank的作用就是给每个顶点一个排名
看来pagerank,以及Page那句网络是个图的想法,对计算机网络的影响还是很深远
现在基本的思想就是
1.任何事物都可以用图表示
2.任何事物的排名都可以用pagerank算法
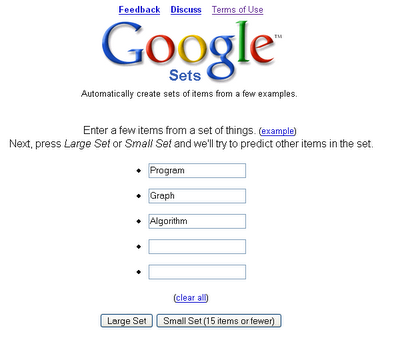
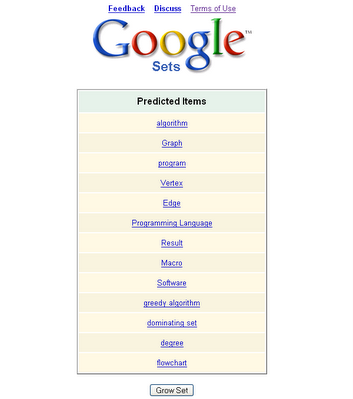
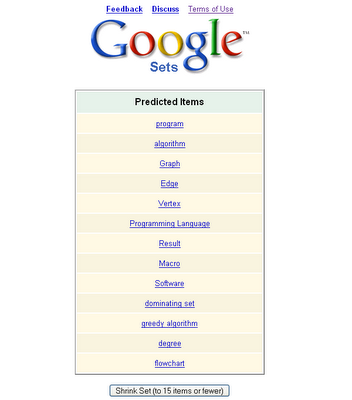
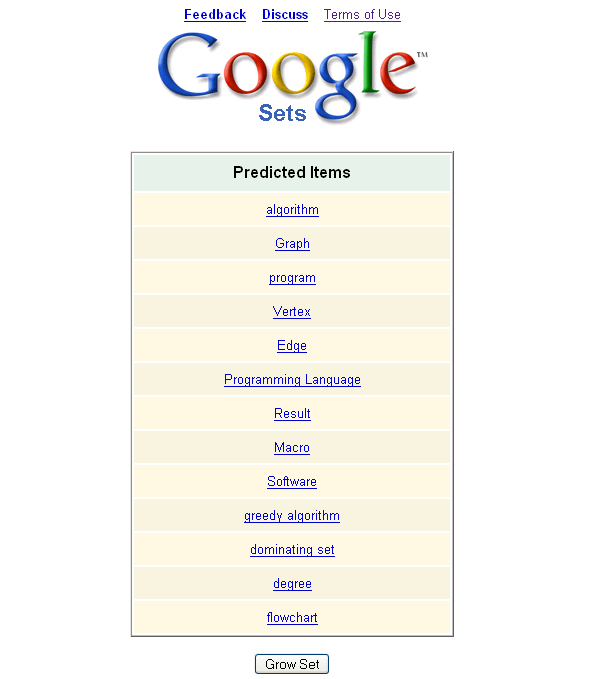
Google Set :关键词 相似度
Google Set 是Google实验室中的一个产品,从他的意思,好像也是致力于词的语义关系的,谷歌给他的解释是: 基于词语例子,自动创建更多的同类词语集成。开来关键词的语义联系目前也是一个热门的研究方向。

2006-12-17
How to Draw Graph(一)
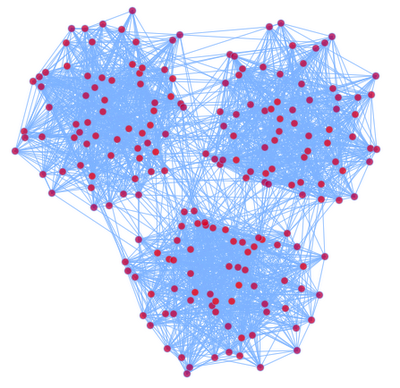
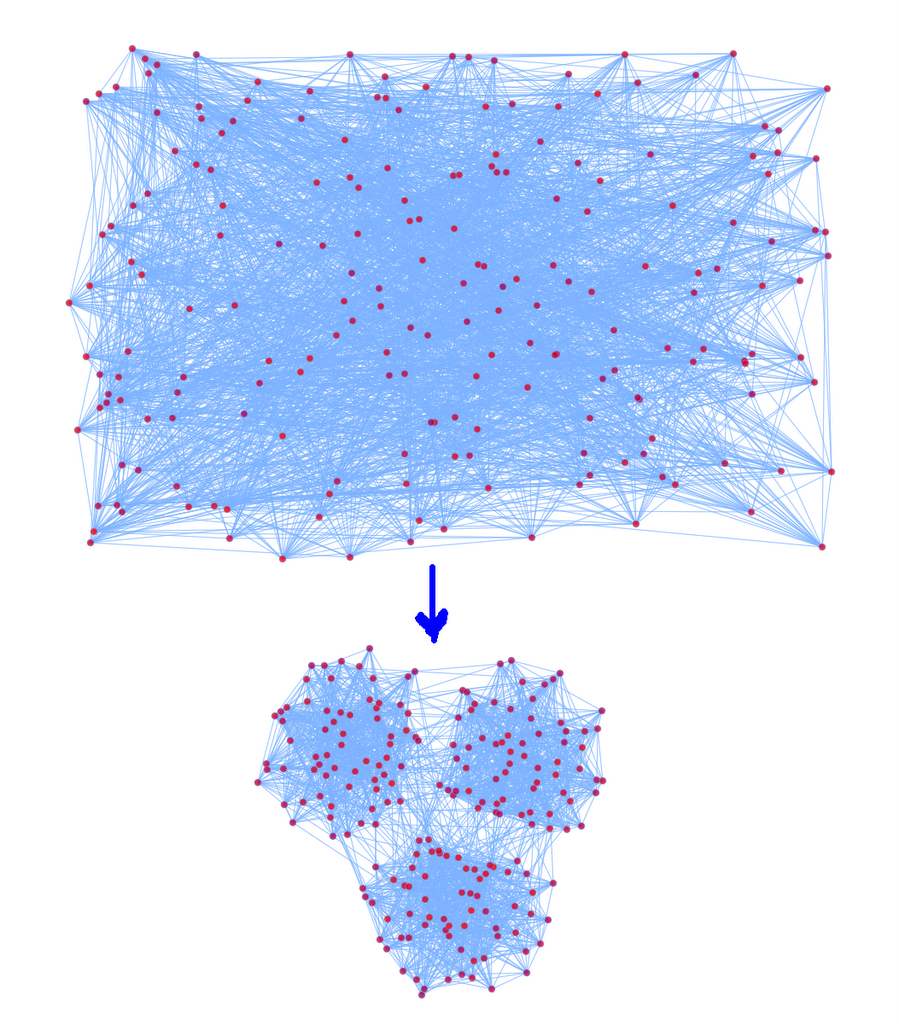
我们这里讨论的图是图论中的图,主要是研究如何将图显示在一个2D的平面上。首先举一个例子,考虑一个随机图:
我们定义3n个顶点,分成3个团(Group),我们定义:
p(vi,vj)为vi和vj有边的概率,如果vi,vj属于同一个团,我们去比较大的概率,否则取比较小的概率。这样我们定义了一个有3个Group的随机图。
如果我们想把这个图在2D平面上显示出来,我们希望显示出来的图也能够显示出这种Group的结构。下面就是我们根据一定算法画出来的图:
对于画图的问题,我们可以如下定义:
给定一个图G{V,E},我们的任务是为每个顶点选择2D坐标vi(x,y),以最小化一个我们定义的能量函数E(V,E)。
首先我们考虑最小化的算法,我们可以用经典的梯度下降法,算法如下:
1. 对顶点vi,i=1,2,......,|V|,随机生成每个顶点的坐标。
2. for t = 1 to T:
for i = 1 to |V|:
计算E相对于vi的梯度下降方向ei,并产生vi的下一个位置 vi(t+1) = vi(t) + alpha * e,alpha是步长
这就是梯度下降法的步骤,当然还可以用很多优化算法,比如共轭梯度法,或者进化计算的方法。下面我们主要考虑如何设计能量函数E,E的设计我们将得到分子结构的启发。
我们定义3n个顶点,分成3个团(Group),我们定义:
p(vi,vj)为vi和vj有边的概率,如果vi,vj属于同一个团,我们去比较大的概率,否则取比较小的概率。这样我们定义了一个有3个Group的随机图。
如果我们想把这个图在2D平面上显示出来,我们希望显示出来的图也能够显示出这种Group的结构。下面就是我们根据一定算法画出来的图:
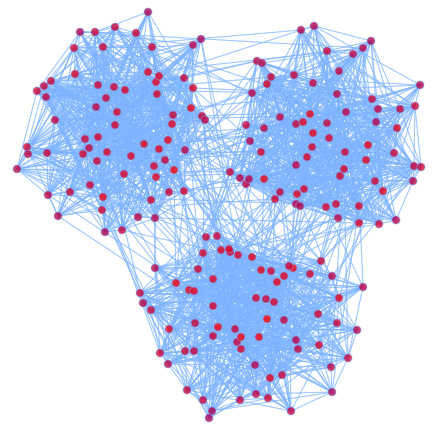
对于画图的问题,我们可以如下定义:
给定一个图G{V,E},我们的任务是为每个顶点选择2D坐标vi(x,y),以最小化一个我们定义的能量函数E(V,E)。
首先我们考虑最小化的算法,我们可以用经典的梯度下降法,算法如下:
1. 对顶点vi,i=1,2,......,|V|,随机生成每个顶点的坐标。
2. for t = 1 to T:
for i = 1 to |V|:
计算E相对于vi的梯度下降方向ei,并产生vi的下一个位置 vi(t+1) = vi(t) + alpha * e,alpha是步长
这就是梯度下降法的步骤,当然还可以用很多优化算法,比如共轭梯度法,或者进化计算的方法。下面我们主要考虑如何设计能量函数E,E的设计我们将得到分子结构的启发。
六度分离(Six Degrees of Separation)理论
转自社会学吧
早在上个世纪60年代,美国著名社会心理学家米尔格伦(Stanley Milgram)就提出了“六级分隔”(Six Degrees of Separation)的理论,并设计了一个连锁信的实验来验证这个假设。他认为,任何两个陌生人都可以通过“朋友的朋友”建立联系,并且他们之间所间隔的人不会超过六个,无论是美国总统与威尼斯的船夫,或热带雨林中的土著与爱斯基摩人。也就是说,最多通过六个人你就能够认识任何一个陌生人。这就是著名的“小世界假设”。
从2001年秋天开始,美国哥伦比亚大学的社会学教授瓦茨(Duncan Watts)组建了一个研究小组,利用Email这一现代通信工具,开始进行“小世界假设”的实验(http://smallworld.columbia.edu)。在1年多时间里,总共有166个国家和地区的6万多名志愿者参与实验,实验结果证明,一封邮件平均被转发6次,即可回到接收者那里。
这个玄妙理论引来了数学家、物理学家和电脑科学家纷纷投入研究,结果发现,世界上许多其他的网络也有极相似的结构。经济活动中的商业联系网络、通过超文本链接的网络、生态系统中的食物链,甚至人类脑神经元,以及细胞内的分子交互作用网络,都有着完全相同的组织结构。
早在上个世纪60年代,美国著名社会心理学家米尔格伦(Stanley Milgram)就提出了“六级分隔”(Six Degrees of Separation)的理论,并设计了一个连锁信的实验来验证这个假设。他认为,任何两个陌生人都可以通过“朋友的朋友”建立联系,并且他们之间所间隔的人不会超过六个,无论是美国总统与威尼斯的船夫,或热带雨林中的土著与爱斯基摩人。也就是说,最多通过六个人你就能够认识任何一个陌生人。这就是著名的“小世界假设”。
从2001年秋天开始,美国哥伦比亚大学的社会学教授瓦茨(Duncan Watts)组建了一个研究小组,利用Email这一现代通信工具,开始进行“小世界假设”的实验(http://smallworld.columbia.edu)。在1年多时间里,总共有166个国家和地区的6万多名志愿者参与实验,实验结果证明,一封邮件平均被转发6次,即可回到接收者那里。
这个玄妙理论引来了数学家、物理学家和电脑科学家纷纷投入研究,结果发现,世界上许多其他的网络也有极相似的结构。经济活动中的商业联系网络、通过超文本链接的网络、生态系统中的食物链,甚至人类脑神经元,以及细胞内的分子交互作用网络,都有着完全相同的组织结构。
2006-10-23
用Python写一个小小的爬虫程序 (Python Spider)
Python有一个urllib的库,可以很方便的从给定的url抓取网页,以下这段程序实现了抓取一个url并存到指定文件的功能: 爬虫工作的基本原理就是,给定一个初始的url,下载这个url的网页,然后找出网页上所有满足下载要求的链接,然后把这些链接对应的url下载下来,然后再找下载下来的这些网页的url,我们可以用广度优先搜索实现这个算法,不过,首先得有一个函数找出网页上所有的满足要求的url,下面这个例子用正则表达式找出url.
爬虫工作的基本原理就是,给定一个初始的url,下载这个url的网页,然后找出网页上所有满足下载要求的链接,然后把这些链接对应的url下载下来,然后再找下载下来的这些网页的url,我们可以用广度优先搜索实现这个算法,不过,首先得有一个函数找出网页上所有的满足要求的url,下面这个例子用正则表达式找出url.

最后就是广度优先搜索了,这个实现起来也很简单:
 作者用上面的算法,感觉速度还行,1小时可以抓10000多网页,可以满足小型系统的要求。
作者用上面的算法,感觉速度还行,1小时可以抓10000多网页,可以满足小型系统的要求。
 爬虫工作的基本原理就是,给定一个初始的url,下载这个url的网页,然后找出网页上所有满足下载要求的链接,然后把这些链接对应的url下载下来,然后再找下载下来的这些网页的url,我们可以用广度优先搜索实现这个算法,不过,首先得有一个函数找出网页上所有的满足要求的url,下面这个例子用正则表达式找出url.
爬虫工作的基本原理就是,给定一个初始的url,下载这个url的网页,然后找出网页上所有满足下载要求的链接,然后把这些链接对应的url下载下来,然后再找下载下来的这些网页的url,我们可以用广度优先搜索实现这个算法,不过,首先得有一个函数找出网页上所有的满足要求的url,下面这个例子用正则表达式找出url.
最后就是广度优先搜索了,这个实现起来也很简单:
 作者用上面的算法,感觉速度还行,1小时可以抓10000多网页,可以满足小型系统的要求。
作者用上面的算法,感觉速度还行,1小时可以抓10000多网页,可以满足小型系统的要求。
2006-10-21
N-最短路径分词算法
NSP分词算法是句子粗分的基本算法,在中科院计算所的文章中有详细描述。但是看了不甚明白,今天实现了这个算法,主要用的还是图论的基本算法Dijkstra算法。
将分词转化为图的最短路径问题
假设要切分一下句子 :主席出现在这里。可将其转化为以下的图:
 从而,找出这个句子的最短切分的问题就可以转化为找出上图的0-->7最短路径的问题。这里所有边的权值都是1。
从而,找出这个句子的最短切分的问题就可以转化为找出上图的0-->7最短路径的问题。这里所有边的权值都是1。
Dijkstra最短路径算法
关于这个算法的描述,网上很多,诸多教科书中也有描述,这里就不详述了。我们现在任务是根据Dijkstra算法计算出的源点0到所有点的最短路径值distace[]来找出所有的最短路径。
比如上图就有2条最短路径,对应两种切分方法:
Input : 源点S,汇点T,distance[]
Dijkstra算法的复杂度取决于图的数据结构,在最好的情况下可以达到VlogV的复杂度。
将分词转化为图的最短路径问题
假设要切分一下句子 :主席出现在这里。可将其转化为以下的图:
 从而,找出这个句子的最短切分的问题就可以转化为找出上图的0-->7最短路径的问题。这里所有边的权值都是1。
从而,找出这个句子的最短切分的问题就可以转化为找出上图的0-->7最短路径的问题。这里所有边的权值都是1。Dijkstra最短路径算法
关于这个算法的描述,网上很多,诸多教科书中也有描述,这里就不详述了。我们现在任务是根据Dijkstra算法计算出的源点0到所有点的最短路径值distace[]来找出所有的最短路径。
比如上图就有2条最短路径,对应两种切分方法:
- 0->2->4->5->7 主席/出现/在/这里
- 0->2->3->5->7 主席/出/现在/这里
Input : 源点S,汇点T,distance[]
- Queue VQ,用来作为广度优先搜索的队列, VQ.append(T)
- while(!VQ.empty())
- Vertex V = VQ.pop()
- if V == S :
- 回溯出一条路径
- for vn in vertexlist :
- if distace[vn] == distacnce[V]-1 and w(vn,V) == 1 :
- VQ.append(vn)
Dijkstra算法的复杂度取决于图的数据结构,在最好的情况下可以达到VlogV的复杂度。
2006-10-19
Emacs 语法提示 --> Semantic
今天搞了一下Emacs的语法提示,参考了王垠的主页关于Semantic的介绍,试用了一下发现不错。
senator可以在已经分析的文件里提取匹配前缀的符号进行补全。有两种补全方式:
(global-set-key "\C-q" 'senator-completion-menu-popup)
(global-set-key "\C-l" 'senator-complete-symbol)
以下是我的屏幕截图:
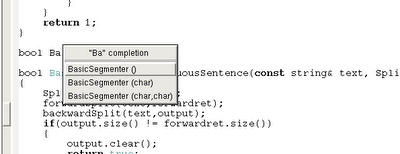
senator可以在已经分析的文件里提取匹配前缀的符号进行补全。有两种补全方式:
- senator-complete-symbol : 补全当前的部分变量名,函数名或类型名。我将它绑定在C-l上。
- senator-completion-menu-popup : 弹出一个补全菜单。我将它绑定在C-q上。
(global-set-key "\C-q" 'senator-completion-menu-popup)
(global-set-key "\C-l" 'senator-complete-symbol)
以下是我的屏幕截图:
2006-10-16
Emacs C && C++ (转载)
http://www.emacs.cn/Doc/CProgram
Emacs对于编辑程序有很多方便的功能,下面是在编辑C程序时常用到的一些功能。
(add-hook 'c-mode-hook 'linux-c-mode)
(add-hook 'c++-mode-hook 'linux-cpp-mode)
;; 设置imenu的排序方式为按名称排序
(setq imenu-sort-function 'imenu--sort-by-name)
(defun linux-c-mode()
;; 将回车代替C-j的功能,换行的同时对齐
(define-key c-mode-map [return] 'newline-and-indent)
(interactive)
;; 设置C程序的对齐风格
(c-set-style "K&R")
;; 自动模式,在此种模式下当你键入{时,会自动根据你设置的对齐风格对齐
(c-toggle-auto-state)
;; 此模式下,当按Backspace时会删除最多的空格
(c-toggle-hungry-state)
;; TAB键的宽度设置为8
(setq c-basic-offset 8)
;; 在菜单中加入当前Buffer的函数索引
(imenu-add-menubar-index)
;; 在状态条上显示当前光标在哪个函数体内部
(which-function-mode)
)
(defun linux-cpp-mode()
(define-key c++-mode-map [return] 'newline-and-indent)
(define-key c++-mode-map [(control c) (c)] 'compile)
(interactive)
(c-set-style "K&R")
(c-toggle-auto-state)
(c-toggle-hungry-state)
(setq c-basic-offset 8)
(imenu-add-menubar-index)
(which-function-mode)
)
(add-hook 'c++-mode-hook 'linux-cpp-mode)
;; 设置imenu的排序方式为按名称排序
(setq imenu-sort-function 'imenu--sort-by-name)
(defun linux-c-mode()
;; 将回车代替C-j的功能,换行的同时对齐
(define-key c-mode-map [return] 'newline-and-indent)
(interactive)
;; 设置C程序的对齐风格
(c-set-style "K&R")
;; 自动模式,在此种模式下当你键入{时,会自动根据你设置的对齐风格对齐
(c-toggle-auto-state)
;; 此模式下,当按Backspace时会删除最多的空格
(c-toggle-hungry-state)
;; TAB键的宽度设置为8
(setq c-basic-offset 8)
;; 在菜单中加入当前Buffer的函数索引
(imenu-add-menubar-index)
;; 在状态条上显示当前光标在哪个函数体内部
(which-function-mode)
)
(defun linux-cpp-mode()
(define-key c++-mode-map [return] 'newline-and-indent)
(define-key c++-mode-map [(control c) (c)] 'compile)
(interactive)
(c-set-style "K&R")
(c-toggle-auto-state)
(c-toggle-hungry-state)
(setq c-basic-offset 8)
(imenu-add-menubar-index)
(which-function-mode)
)
一此有用的快捷键:
- C-c C-c 注释区域,此命令等同于M-x comment-region,但C-c C-c仅适用于C程序,而M-x comment-region适用于任何程序。
- C-u C-c C-c :: 在c-mode下C-c C-c comment-region,C-u C-c C-c是uncomment-region.
- C-M-\ 对齐一个区域,用些命令要先保证区域已经被选中,则用系统默认的对齐方式进行对齐。
- C-c C-q 自动对齐一个函数。将光标停在一个函数体内,然后按这个键,可以自动将函数的内容按默认的对齐方式对齐。
- TAB 重新缩进当前行
- C-c . 设置缩进风格(按TAB键可列出可用的风格,缺省的为gnu,其缩进为2个字符;linux为8个;k&r为5个…)
- M-/ 自动补齐(缓冲区中能找得到的串)
- M-; 行尾加入注释
- C-c C-e 扩展宏,察看当前宏的值
- C-c C-\ 通过'\'连接多行代码
子模式
auto-state 当你输入时自动缩进,自动换行
hungry-state 当你Backspace时,自动删除尽可能多的空白和空行
- C-c C-t 同时转换(开/关)auto-state和hungry-state子模式
- C-c C-a 转换 auto-state 子模式
- C-c C-d 转换 hungry-state 子模式
编译与调试
- M-x compile 可以输入命令对程序文件进行编译,编译器的输出在一个另外一个子窗口中显示,将光标移到*compilation* 中的一行错误提示上击回车(或直接鼠标中键)即可在程序中定位错误。
- M-x gdb RET 调试
- C-x ` (出错信息中)下一个错误,一个窗口显示错误信息,另一个显示源码的出错位置
- C-c C-c 转到出错位置
启动gdb调试器后,光标在源码文件缓冲区中时:
- C-x SPC 在当前行设置断点
- C-x C-a C-s step
- C-x C-a C-n next
- C-x C-a C-t tbreak
- C-x C-a C-r continue
2006-10-15
中国姓氏:单姓和复姓
中国目前的复姓有以下80个 :
欧阳、太史、端木、 上官、司马、东方、独孤、南宫、万俟、闻人、夏侯、诸葛、尉迟、公羊、赫连、澹台、皇甫、宗政、濮阳、公冶、太叔、申屠、公孙、慕容、仲孙、钟离、长孙、 宇文、司徒、鲜于、司空、闾丘、子车、亓官、司寇、巫马、公西、颛孙、壤驷、公良、漆雕、乐正、宰父、谷梁、拓跋、夹谷、轩辕、令狐、段干、百里、呼延、 东郭、南门、羊舌、微生、公户、公玉、公仪、梁丘、公仲、公上、公门、公山、公坚、左丘、公伯、西门、公祖、第五、公乘、贯丘、公皙、南荣、东里、东宫、 仲长、子书、子桑、即墨、达奚、褚师
中国排名前300名的姓氏 :
1李 2王 3张 4刘 5陈 6杨 7赵 8黄 9周 10吴
11徐 12孙 13胡 14朱 15高 16林 17何 18郭 19马 20罗
21梁 22宋 23郑 24谢 25韩 26唐 27冯 28于 29董 30萧
31程 32曹 33袁 34邓 35许 36傅 37沈 38曾 39彭 40吕
41苏 42卢 43蒋 44蔡 45贾 46丁 47魏 48薛 49叶 50阎
51余 52潘 53杜 54戴 55夏 56钟 57汪 58田 59任 60姜
61范 62方 63石 64姚 65谭 66廖 67邹 68熊 69金 70陆
71郝 72孔 73白 74崔 75康 76毛 77邱 78秦 79江 80史
81顾 82侯 83邵 84孟 85龙 86万 87段 88曹 89钱 90汤
91尹 92黎 93易 94常 95武 96乔 97贺 98赖 99龚 100文
101庞102樊103兰104殷105施106陶107洪108翟109安110颜
111倪112严113牛114温115芦116季117俞118章119鲁120葛
121伍122韦123申124尤125毕126聂127丛128焦129向130柳
131邢132路133岳134齐135沿136梅137莫138庄139辛140管
141祝142左143涂144谷145祁146时147舒148耿149牟150卜
151路152詹153关154苗155凌156费157纪158靳159盛160童
161欧162甄163项164曲165成166游167阳168裴169席170卫
171查172屈173鲍174位175覃176霍177翁178隋179植180甘
181景182薄183单184包185司186柏187宁188柯189阮190桂
191闵192欧阳193解194强195柴196华197车198冉199房200边
201辜201吉203饶204刁205瞿206戚207丘208古209米210池
211滕212晋213苑214邬215臧216畅217宫218来219嵺220苟
221全222褚223廉224简225娄226盖227符228奚229木230穆
231党232燕233郎234邸235冀236谈237姬238屠239连240郜
241晏242栾243郁244商245蒙246计247喻248揭249窦250迟
251宇252敖253糜254鄢255冷256卓257花258仇259艾260蓝
261都262巩263稽264井265练266仲267乐268虞269卞270封
271竺272冼273原274官275衣276楚277佟278栗279匡280宗
281应282台283巫284鞠285僧286桑287荆288谌289银290扬
291明292沙293薄294伏295岑296习297胥298保299和300蔺
欧阳、太史、端木、 上官、司马、东方、独孤、南宫、万俟、闻人、夏侯、诸葛、尉迟、公羊、赫连、澹台、皇甫、宗政、濮阳、公冶、太叔、申屠、公孙、慕容、仲孙、钟离、长孙、 宇文、司徒、鲜于、司空、闾丘、子车、亓官、司寇、巫马、公西、颛孙、壤驷、公良、漆雕、乐正、宰父、谷梁、拓跋、夹谷、轩辕、令狐、段干、百里、呼延、 东郭、南门、羊舌、微生、公户、公玉、公仪、梁丘、公仲、公上、公门、公山、公坚、左丘、公伯、西门、公祖、第五、公乘、贯丘、公皙、南荣、东里、东宫、 仲长、子书、子桑、即墨、达奚、褚师
中国排名前300名的姓氏 :
1李 2王 3张 4刘 5陈 6杨 7赵 8黄 9周 10吴
11徐 12孙 13胡 14朱 15高 16林 17何 18郭 19马 20罗
21梁 22宋 23郑 24谢 25韩 26唐 27冯 28于 29董 30萧
31程 32曹 33袁 34邓 35许 36傅 37沈 38曾 39彭 40吕
41苏 42卢 43蒋 44蔡 45贾 46丁 47魏 48薛 49叶 50阎
51余 52潘 53杜 54戴 55夏 56钟 57汪 58田 59任 60姜
61范 62方 63石 64姚 65谭 66廖 67邹 68熊 69金 70陆
71郝 72孔 73白 74崔 75康 76毛 77邱 78秦 79江 80史
81顾 82侯 83邵 84孟 85龙 86万 87段 88曹 89钱 90汤
91尹 92黎 93易 94常 95武 96乔 97贺 98赖 99龚 100文
101庞102樊103兰104殷105施106陶107洪108翟109安110颜
111倪112严113牛114温115芦116季117俞118章119鲁120葛
121伍122韦123申124尤125毕126聂127丛128焦129向130柳
131邢132路133岳134齐135沿136梅137莫138庄139辛140管
141祝142左143涂144谷145祁146时147舒148耿149牟150卜
151路152詹153关154苗155凌156费157纪158靳159盛160童
161欧162甄163项164曲165成166游167阳168裴169席170卫
171查172屈173鲍174位175覃176霍177翁178隋179植180甘
181景182薄183单184包185司186柏187宁188柯189阮190桂
191闵192欧阳193解194强195柴196华197车198冉199房200边
201辜201吉203饶204刁205瞿206戚207丘208古209米210池
211滕212晋213苑214邬215臧216畅217宫218来219嵺220苟
221全222褚223廉224简225娄226盖227符228奚229木230穆
231党232燕233郎234邸235冀236谈237姬238屠239连240郜
241晏242栾243郁244商245蒙246计247喻248揭249窦250迟
251宇252敖253糜254鄢255冷256卓257花258仇259艾260蓝
261都262巩263稽264井265练266仲267乐268虞269卞270封
271竺272冼273原274官275衣276楚277佟278栗279匡280宗
281应282台283巫284鞠285僧286桑287荆288谌289银290扬
291明292沙293薄294伏295岑296习297胥298保299和300蔺
2006-10-14
Emacs ECB 的安装(转载)
ECB 是Emacs中浏览代码的一个工具,今天刚装了,感觉不错 。下面分享一下安装的方法,嘿嘿。由于是参考了别人的安装方法,所以原文转载:
一、下载
ECB是CEDET工具包中的一项,可以从以下地址下载:
http://sourceforge.net/projects/ecb/
他还需要其她几个软件包
speedbar
eieio
semantic
下载地址:
http://sourceforge.net/projects/cedet/
将这几个软件包解压到emacs的目录下,我的emacs配置目录为
/usr/local/share/emacs/21.1/
site-lisp/
ecb
speedbar
eieio
semantic
然后进行配置,顺序为:speedbar eieio semantic ecb
二、配置
1.speedbar配置
在site-lisp/subdirs.el中加入
(add-to-list 'load-path "/path/speedbar")
我的为:
(add-to-list 'load-path "/usr/local/share/emacs/speedbar")
然后加入:
(autoload 'speedbar-frame-mode "speedbar" "Popup a speedbar frame" t)
(autoload 'speedbar-get-focus "speedbar" "Jump to speedbar frame" t)
(global-set-key [(f4)] 'speedbar-get-focus)
如果你用Emacs,加入:
(define-key-after (lookup-key global-map [menu-bar tools])
[speedbar] '("Speedbar" . speedbar-frame-mode) [calendar])
如果你用XEmacs,加入:
(add-menu-button '("Tools")
["Speedbar" speedbar-frame-mode
:style toggle
:selected (and (boundp 'speedbar-frame)
(frame-live-p speedbar-frame)
(frame-visible-p speedbar-frame))]
"--")
;; Texinfo fancy chapter tags
(add-hook 'texinfo-mode-hook (lambda () (require 'sb-texinfo)))
;; HTML fancy chapter tags
(add-hook 'html-mode-hook (lambda () (require 'sb-html)))
(autoload 'rpm "sb-rpm" "Rpm package listing in speedbar.")
;; w3 link listings
(autoload 'w3-speedbar-buttons "sb-w3" "s3 specific speedbar button generator.")
XEmacs Emacs 20.2版本以前的加入:
;; chapter listings
(autoload 'Info-speedbar-buttons "sb-info" "Info specific speedbar button generator.")
;; folder listings
(autoload 'rmail-speedbar-buttons "sb-rmail" "Rmail specific speedbar button generator.")
;; current stack display
(autoload 'gud-speedbar-buttons "sb-gud" "GUD specific speedbar button generator.")
以后的加入
(eval-after-load "info" '(require 'sb-info))
2.eieio 配置
在site-lisp/subdirs.el中加入
(add-to-list 'load-path "/path/eieio")
我的为:
(add-to-list 'load-path "/usr/local/share/emacs/eieio")
3.semantic 配置
在site-lisp/subdirs.el中加入
(add-to-list 'load-path "/path/to/semantic")
(setq semantic-load-turn-everything-on t)
我的为:
(add-to-list 'load-path "/usr/local/share/emacs/semantic")
(setq semantic-load-turn-everything-on t)
4.ecb 配置
在site-lisp/subdirs.el中加入
(add-to-list 'load-path "/path/ecb")
我的为:
(add-to-list 'load-path "/usr/local/share/emacs/ecb")
在~/.emacs中加入
(require 'ecb)
三、使用
M-x ecb-activate 激活ECB
M-x ecb-show-help 查看帮助
四、其它
如果你想加速这些程序的执行,那么就要将EL文件编译成ELC文件。
查看相应程序的Makefile文件,修改LOADPATH变量,然后make即可
一、下载
ECB是CEDET工具包中的一项,可以从以下地址下载:
http://sourceforge.net/projects/ecb/
他还需要其她几个软件包
speedbar
eieio
semantic
下载地址:
http://sourceforge.net/projects/cedet/
将这几个软件包解压到emacs的目录下,我的emacs配置目录为
/usr/local/share/emacs/21.1/
site-lisp/
ecb
speedbar
eieio
semantic
然后进行配置,顺序为:speedbar eieio semantic ecb
二、配置
1.speedbar配置
在site-lisp/subdirs.el中加入
(add-to-list 'load-path "/path/speedbar")
我的为:
(add-to-list 'load-path "/usr/local/share/emacs/speedbar")
然后加入:
(autoload 'speedbar-frame-mode "speedbar" "Popup a speedbar frame" t)
(autoload 'speedbar-get-focus "speedbar" "Jump to speedbar frame" t)
(global-set-key [(f4)] 'speedbar-get-focus)
如果你用Emacs,加入:
(define-key-after (lookup-key global-map [menu-bar tools])
[speedbar] '("Speedbar" . speedbar-frame-mode) [calendar])
如果你用XEmacs,加入:
(add-menu-button '("Tools")
["Speedbar" speedbar-frame-mode
:style toggle
:selected (and (boundp 'speedbar-frame)
(frame-live-p speedbar-frame)
(frame-visible-p speedbar-frame))]
"--")
;; Texinfo fancy chapter tags
(add-hook 'texinfo-mode-hook (lambda () (require 'sb-texinfo)))
;; HTML fancy chapter tags
(add-hook 'html-mode-hook (lambda () (require 'sb-html)))
(autoload 'rpm "sb-rpm" "Rpm package listing in speedbar.")
;; w3 link listings
(autoload 'w3-speedbar-buttons "sb-w3" "s3 specific speedbar button generator.")
XEmacs Emacs 20.2版本以前的加入:
;; chapter listings
(autoload 'Info-speedbar-buttons "sb-info" "Info specific speedbar button generator.")
;; folder listings
(autoload 'rmail-speedbar-buttons "sb-rmail" "Rmail specific speedbar button generator.")
;; current stack display
(autoload 'gud-speedbar-buttons "sb-gud" "GUD specific speedbar button generator.")
以后的加入
(eval-after-load "info" '(require 'sb-info))
2.eieio 配置
在site-lisp/subdirs.el中加入
(add-to-list 'load-path "/path/eieio")
我的为:
(add-to-list 'load-path "/usr/local/share/emacs/eieio")
3.semantic 配置
在site-lisp/subdirs.el中加入
(add-to-list 'load-path "/path/to/semantic")
(setq semantic-load-turn-everything-on t)
我的为:
(add-to-list 'load-path "/usr/local/share/emacs/semantic")
(setq semantic-load-turn-everything-on t)
4.ecb 配置
在site-lisp/subdirs.el中加入
(add-to-list 'load-path "/path/ecb")
我的为:
(add-to-list 'load-path "/usr/local/share/emacs/ecb")
在~/.emacs中加入
(require 'ecb)
三、使用
M-x ecb-activate 激活ECB
M-x ecb-show-help 查看帮助
四、其它
如果你想加速这些程序的执行,那么就要将EL文件编译成ELC文件。
查看相应程序的Makefile文件,修改LOADPATH变量,然后make即可
Emacs 的一些技巧
- 注释一段代码:选中要注释的区域,按 C-c C-c就可以注释这一区域,如果要取消注释,用鼠标选择这一区域,按C-u C-c C-c。
- 改变编辑器的字体,M-x set-default-font 然后按tab键,就会出现所有的font,或者也可以修改.emacs配置文件,我的配置文件是:
(set-default-font "-adobe-courier-medium-r-normal--14-100-100-100-m-90-iso10646-1") - 改变缩进方式,C-c .,然后按Tab键,可以选择缩进方式,我用的是linux.
2006-10-02
Windows和Solaris上Boost安装和编译
文章转自 http://www.stlchina.org/twiki/bin/view.pl/Main/BoostInstall
(注:这一步其实可以省略,直接在(三)中通过-s输入到命令行即可,但设置可以让命令行更清晰、简单一点。) 3.1 Windows
我的电脑点右键->属性->高级->环境变量->user variable或system variable中:
PATH最后添加bjam存放目录,如:
$BOOSTDIR\tools\build\jam_src\bin.ntx86
新建环境变量MSVCDIR,并在变量值一栏中填入VC安装目录,如:
X:\Program Files\Microsoft Visual Studio\VC98
新建环境变量:
PYTHON_ROOT=X:\Program Files\Python2.3.4
PYTHON_VERSION=2.3
3.2 Solaris 9
在.profile中PATH后添加编译后的jam的存放目录。
并增加
PYTHON_VERSION=2.3
export PYTHON_VERSION
注意,无需设置PYTHON_ROOT,Solaris下jam会自动处理。
0 前言
大卫注:这是当初研究boost时的笔记,最近看到论坛上有人问,所以就贴出来共享一下。其实个人认为,boost目前还不适于进行应用开发,毕竟 boost库太大了(当然,你可以只用一部分,但程序的可维护性始终是个问题),除非你想一探C++研究前沿的Meta Programming这个Generic Programming的神奇世界。强烈建议boost的研究者在研究boost之前研究一下一个小得多的模板库loki,boost中的很多让你无法理 解的技术在loki库中被大量运用,并且这个库的作者专门写了Modern C++ Design来解说该库的实现。此外,如果你要研究boost,开始时不要编译所有的库,如Python,thread,test等,因为等你花几个小时 编译完了,你可能发现,你根本就用不到这些库,或者对它根本就不感兴趣,等到你研究完比较小的几个库,对boost有了充分了解的时候再来编译也不迟。注:
- 开始前请确认你的OS中已经安装了适当的编译器,以下Windows环境中以Windows 2000 + VC6为例,Unix环境中以Solaris 9 + GCC 3.4.2为例;
- 以下以$BOOSTDIR表示boost的存放目录,请自行根据实际情况进行修改。
1 下载 Boost + 解包(略)
2 编译jam
2.1Windows
到$BOOSTDIR\tools\build\jam_src 下执行build.bat对jam进行编译,编译结果将存放在$BOOSTDIR\ tools\build\jam_src\bin.ntx86下。如果你在执行该批处理程序过程中遇到问题,如报告无法找到编译器相关程序,请执行 X:\Program Files\Microsoft Visual Studio\VC98\Bin\VCVARS32.bat 以建立VC的基本环境变量。2.2 Solaris 9
到$BOOSTDIR\tools\build\jam_src下执行./build.sh对jam进行编译,编译结果将存放在$BOOSTDIR\tools\build\jam_src\bin.solarisx86下。3 设置环境变量
(注:这一步其实可以省略,直接在(三)中通过-s输入到命令行即可,但设置可以让命令行更清晰、简单一点。)
3.1 Windows
我的电脑点右键->属性->高级->环境变量->user variable或system variable中:PATH最后添加bjam存放目录,如:
$BOOSTDIR\tools\build\jam_src\bin.ntx86
新建环境变量MSVCDIR,并在变量值一栏中填入VC安装目录,如:
X:\Program Files\Microsoft Visual Studio\VC98
新建环境变量:
PYTHON_ROOT=X:\Program Files\Python2.3.4
PYTHON_VERSION=2.3
3.2 Solaris 9
在.profile中PATH后添加编译后的jam的存放目录。并增加
PYTHON_VERSION=2.3
export PYTHON_VERSION
注意,无需设置PYTHON_ROOT,Solaris下jam会自动处理。
4 编译Boost
4.1 Windows
命令: jam -sBOOST_ROOT=. -sTOOLS=msvc "-sBUILD=debug release
以上命令解释如下:
-s 即set,设置环境变量;
BOOST_ROOT boost的存放目录
TOOLS 你选择的toolset,如gcc、msvc(即vc6)、vc7.1,此外还有gcc-stlport、msvc-stlport、vc7.1- stlport,表示同时使用stlport。具体支持何种toolset,大家可以自行到$BOOSTDIR\tools\build\v1看个究竟。 BUILD 编译类型,上述选项表示编译出支持static和dynamic链接的debug和release版本(4个版本)。
编译后的lib、dll将被copy到$BOOSTDIR\bin\boost\libs目录下,但是这些lib、dll分散在不同的目 录下,为了便于使用,可以在上述目录下分别查找*.lib和*.dll找出这些文件,然后将他们分别全部copy到VC的lib目录和Windows的 System32目录,也可以自己建立一个专门用于存放boost的lib文件的目录,然后 依次选择Tools->Options->Directories->Library files,将上述目录路径添加到VC的环境设置中。
4.2 Solaris 9
到$BOOSTDIR下执行以下命令:
jam -sBOOST_ROOT=. -sTOOLS=gcc "-sBUILD=debug release
但建议用如下命令:
jam -sBOOST_ROOT=. -sTOOLS=gcc "-sBUILD=release
这样可以极大加快编译的速度,同时,个人认为像boost这样大的库,最好还是采用动态链接以减小目标程序的size,就像libstdc++,还没有见过有人去静态链接libstdc++.a,虽然系统中提供了这个静态库。
2006-09-05
How to Use Taucs Under Windows
Taucs is a C library of sparse linear solvers.
First, you can visit here to get a copy of Taucs Source Code.
Compile Under Window
unzip the package you download from internet. Go in to the folder, first run configure.exe to generate a makefile. Then, type nmake in command line, taucs will be compiled and builded.
Programming with Taucs under Visual Studio
Here, I only present an example.
First, create a new project, and add taucs libs folder to the project. Then, type taucs libs in Property->Linker->Input->additional dependencies.
Second, you can use taucs librarys, in C++, you must include header files like this:
extern "C" {
#include "taucs.h"
#include "taucs_private.h"
}
First, you can visit here to get a copy of Taucs Source Code.
Compile Under Window
unzip the package you download from internet. Go in to the folder, first run configure.exe to generate a makefile. Then, type nmake in command line, taucs will be compiled and builded.
Programming with Taucs under Visual Studio
Here, I only present an example.
First, create a new project, and add taucs libs folder to the project. Then, type taucs libs in Property->Linker->Input->additional dependencies.
Second, you can use taucs librarys, in C++, you must include header files like this:
extern "C" {
#include "taucs.h"
#include "taucs_private.h"
}
2006-08-29
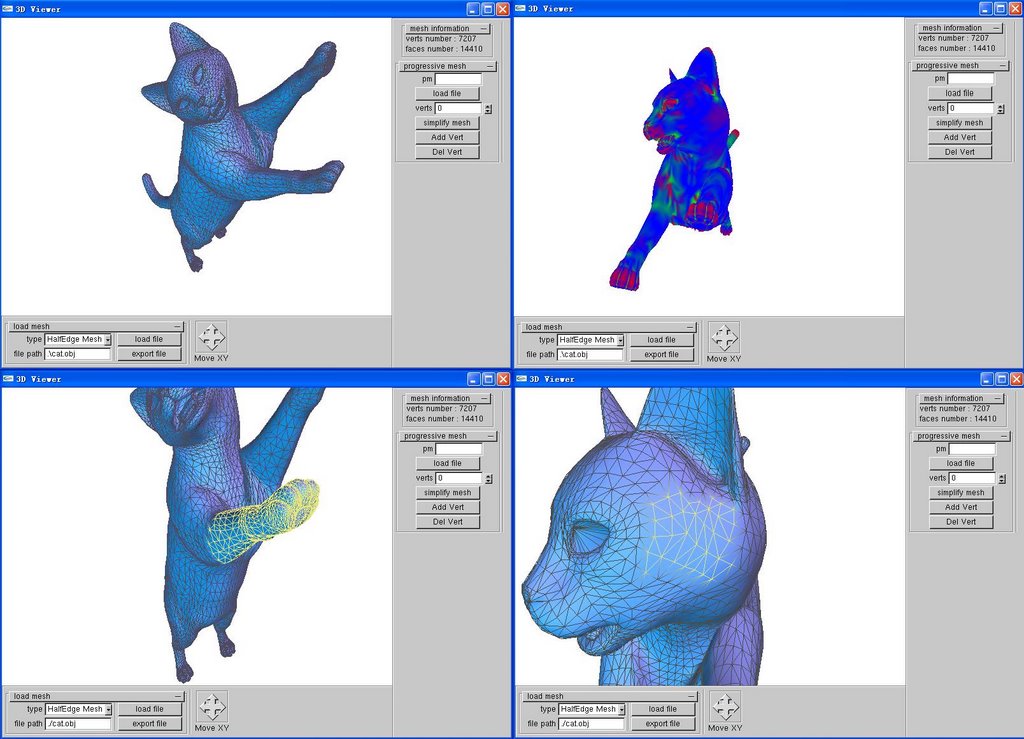
View3D ---- A 3D Viewer
View3D is a 3D Viewer Degigned by me, it can realize rotation, translation, scaling, selection of a 3D model. It support obj file format, which means it can load and save 3D mesh models by obj file format.
I use halfedge mesh structure in the software, and I also realize my undergraduate thesis project "Progressive Mesh" under this software.
This Software is designed by OpenGL, anyone who want to get source can emai me :
xlvector@gmail.com
Flollowing is Screen Capture of Software View3D:
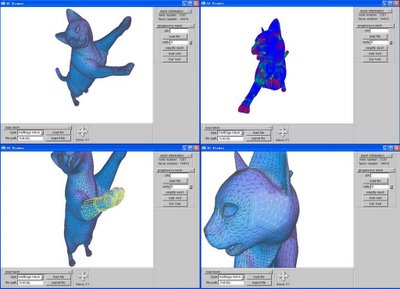

I use halfedge mesh structure in the software, and I also realize my undergraduate thesis project "Progressive Mesh" under this software.
This Software is designed by OpenGL, anyone who want to get source can emai me :
xlvector@gmail.com
Flollowing is Screen Capture of Software View3D:
2006-08-21
How To Compile OpenCV in Linux
Under Linux, how to compile OpenCV with some libraries not in standard path ?
The solution is to use the CFLAGS, CPPFLAGS and LDFLAGS environment variables at configure time. For example, if you have ffmpeg library in one you your own directories, you can do (all on one command line):
./configure CFLAGS=-I/where/is/ffmpeg/include CPPFLAGS=-I/where/is/ffmpeg/include LDFLAGS=-L/where/is/ffmpeg/lib
How to compile C samples under Linux ?
If OpenCV is installed in a standard path, you can quickly compile all the C samples with:
cd /where/you/have/the/c/samples
sh ./build_all.sh
If OpenCV is not installed in a standard path, you need to setup the PKG_CONFIG_PATH variable. For example (assuming you are using a sh-based shell, like bash or zsh):
cd /where/you/have/the/c/samples
PKG_CONFIG_PATH=/where/you/have/installed/opencv/lib/pkgconfig:${PKG_CONFIG_PATH}
export PKG_CONFIG_PATH
sh ./build_all.sh
You can check that the PKG_CONFIG_PATH is correct by doing either:
pkg-config --cflags opencv
pkg-config --libs opencv
You must have something like:
$ pkg-config --cflags opencv
-I/where/you/have/installed/opencv/include/opencv
$ pkg-config --libs opencv
-L/com/softs/opencv-cvs/cvs-dev-i686/lib -lcxcore -lcv -lhighgui -lcvaux
How can I compile and link some OpenCV based program under Linux ?
The best way is to use pkg-config. Just define the correct PKG_CONFIG_PATH:
PKG_CONFIG_PATH=/where/you/have/installed/opencv/lib/pkgconfig:${PKG_CONFIG_PATH}
export PKG_CONFIG_PATH
And then, compile your program like:
gcc `pkg-config --cflags opencv` `pkg-config --libs opencv` -o my-opencv-prgm my-opencv-prgm.c
or simply:
gcc `pkg-config --cflags --libs opencv` -o my-opencv-prgm my-opencv-prgm.c
if that fails try:
gcc -I/home/intel/opencv/include -L/home/intel/opencv/lib -lopencv -lhighgui -lstdc++ opencv0.c -o opencv0
What if I get an error about OpenCV libraries when running a program?
If, after following the instructions above, your program compiles, but gives an error message that a library cannot be found when it is run, on Fedora systems:
create a file called opencv.conf in /etc/ld.so.conf.d/ which contains the path to your opencv libraries (by default /usr/local/lib).
become root and run ldconfig.
2006-08-20
利用Video4Linux获取摄像头数据
Video4Linux是Linux下用于获取视频和音频数据的API接口,在这篇文章中,我着重阐述如何利用Video4Linux获取摄像头数据,以实现连续影像的播放。
1. 摄像头的安装
在Linux下常用的摄像头驱动是spca5xx, 这是一个通用驱动,读者可以在以下网站下到这个驱动 http://mxhaard.free.fr/download.html。这个网站还给出了这款驱动支持
1. 摄像头的安装
在Linux下常用的摄像头驱动是spca5xx, 这是一个通用驱动,读者可以在以下网站下到这个驱动 http://mxhaard.free.fr/download.html。这个网站还给出了这款驱动支持
的摄像头的种类。另外,ov511芯片直接就支持Linux,使用者款芯片的摄像头有网眼V2000。我使用的是网眼V2000的摄像头,和Z-Star 301p+现代7131R芯片的摄像头。后一
种需要spca5xx的驱动。关于spca5xx的安装方法,网上有很多介绍,这里就不说了。
2. 摄像头的调试
安装好摄像头后,为了测试摄像头能否正常工作,可以用一下软件。比较著名的是xawtv,在网上搜以下可以下载到。安装好后,打开xawtv则可以调试摄像头。
3. Video4Linux 编程获取数据。
现有的video4linux有两个版本,v4l和v4l2。本文主要是关于v4l的编程。利用v4l API获取视频图像一般有以下几步:
a> 打开设备
b> 设置设备的属性,比如图像的亮度,对比度等等
c> 设定传输格式和传输方式
d> 开始传输数据,一般是一个循环,用以连续的传输数据
e> 关闭设备
下面具体介绍v4l编程的过程。首先指出,在video4linux编程时要包含头文件,其中包含了video4linux的数据结构和函数定义。
1)v4l的数据结构
在video4linux API中定义了如下数据结构,详细的数据结构定义可以参考v4l API的文档,这里就编程中经常使用的数据结构作出说明。
首先我们定义一个描述设备的数据结构,它包含了v4l中定义的所有数据结构:
typedef struct _v4ldevice
{
int fd; //设备号
struct video_capability capability;
struct video_channel channel[10];
struct video_picture picture;
struct video_clip clip;
struct video_window window;
struct video_capture capture;
struct video_buffer buffer;
struct video_mmap mmap;
struct video_mbuf mbuf;
struct video_unit unit;
unsigned char *map; //mmap方式获取数据时,数据的首地址
pthread_mutex_t mutex;
int frame;
int framestat[2];
int overlay;
}v4ldevice;
下面解释上面这个数据结构中包含的数据结构,这些结构的定义都在中。
* struct video_capability
name[32] Canonical name for this interface
type Type of interface
channels Number of radio/tv channels if appropriate
audios Number of audio devices if appropriate
maxwidth Maximum capture width in pixels
maxheight Maximum capture height in pixels
minwidth Minimum capture width in pixels
minheight Minimum capture height in pixels
这一个数据结构是包含了摄像头的属性,name是摄像头的名字,maxwidth maxheight是摄像头所能获取的最大图像大小,用橡素作单位。
在程序中,通过ioctl函数的VIDIOCGCAP控制命令读写设备通道已获取这个结构,有关ioctl的使用,比较复杂,这里就不说了。下面列出获取这一数据结构的代码:
int v4lgetcapability(v4ldevice *vd)
{
if(ioctl(vd->fd, VIDIOCGCAP, &(vd->capability)) < 0) {
v4lperror("v4lopen:VIDIOCGCAP");
return -1;
}
return 0;
}
* struct video_picture
brightness Picture brightness
hue Picture hue (colour only)
colour Picture colour (colour only)
contrast Picture contrast
whiteness The whiteness (greyscale only)
depth The capture depth (may need to match the frame buffer depth)
palette Reports the palette that should be used for this image
这个数据结构主要定义了图像的属性,诸如亮度,对比度,等等。这一结构的获取通过ioctl发出VIDIOCGPICT控制命令获取。
* struct video_mbuf
size The number of bytes to map
frames The number of frames
offsets The offset of each frame
这个数据结构在用mmap方式获取数据时很重要:
size表示图像的大小,如果是640*480的彩色图像,size=640*480*3
frames表示帧数
offsets表示每一帧在内存中的偏移地址,通过这个值可以得到数据在图像中的地址。
得到这个结构的数据可以用ioctl的VIDIOCGMBUF命令。源码如下:
int v4lgetmbuf(v4ldevice *vd)
{
if(ioctl(vd->fd, VIDIOCGMBUF, &(vd->mbuf))<0) {
v4lperror("v4lgetmbuf:VIDIOCGMBUF");
return -1;
}
return 0;
}
而数据的地址可以有以下方式计算:
unsigned char *v4lgetaddress(v4ldevice *vd)
{
return (vd->map + vd->mbuf.offsets[vd->frame]);
}
2)获取影像mmap方式。
在video4linux下获取影像有两种方式:overlay和mmap。由于我的摄像头不支持overlay方式,所以这里只谈mmap方式。
mmap方式是通过内存映射的方式获取数据,系统调用ioctl的VIDIOCMCAPTURE后,将图像映射到内存中,
然后可以通过前面的v4lgetmbuf(vd)函数和v4lgetaddress(vd)函数获得数据的首地址,这是李可以选择是将它显示出来还是放到别的什么地方。
下面给出获取连续影像的最简单的方法(为了简化,将一些可去掉的属性操作都去掉了):
char* devicename="/dev/video0";
char* buffer;
v4ldevice device;
int width = 640;
int height = 480;
int frame = 0;
v4lopen("/dev/video0",&device); //打开设备
v4lgrabinit(&device,width,height); //初始化设备,定义获取的影像的大小
v4lmmap(&device); //内存映射
v4lgrabstart(&device,frame); //开始获取影像
while(1){
v4lsync(&device,frame); //等待传完一帧
frame = (frame+1)%2; //下一帧的frame
v4lcapture(&device,frame); //获取下一帧
buffer = (char*)v4lgetaddress(&device);//得到这一帧的地址
//buffer给出了图像的首地址,你可以选择将图像显示或保存......
//图像的大小为 width*height*3
..........................
}
为了更好的理解源码,这里给出里面的函数的实现,这里为了简化,将所有的出错处理都去掉了。
int v4lopen(char *name, v4ldevice *vd)
{
int i;
if((vd->fd = open(name,O_RDWR)) < 0) {
return -1;
}
if(v4lgetcapability(vd))
return -1;
}
int v4lgrabinit(v4ldevice *vd, int width, int height)
{
vd->mmap.width = width;
vd->mmap.height = height;
vd->mmap.format = vd->picture.palette;
vd->frame = 0;
vd->framestat[0] = 0;
vd->framestat[1] = 0;
return 0;
}
int v4lmmap(v4ldevice *vd)
{
if(v4lgetmbuf(vd)<0)
return -1;
if((vd->map = mmap(0, vd->mbuf.size, PROT_READ|PROT_WRITE, MAP_SHARED, vd->fd, 0)) < 0) {
return -1;
}
return 0;
}
int v4lgrabstart(v4ldevice *vd, int frame)
{
vd->mmap.frame = frame;
if(ioctl(vd->fd, VIDIOCMCAPTURE, &(vd->mmap)) < 0) {
return -1;
}
vd->framestat[frame] = 1;
return 0;
}
int v4lsync(v4ldevice *vd, int frame)
{
if(ioctl(vd->fd, VIDIOCSYNC, &frame) < 0) {
return -1;
}
vd->framestat[frame] = 0;
return 0;
}
int c4lcapture(v4ldevice *vd, int frame)
{
vd->mmap.frame = frame;
if(ioctl(vd->fd, VIDIOCMCAPTURE, &(vd->mmap)) < 0) {
return -1;
}
vd->framestat[frame] = 1;
return 0;
}
2. 摄像头的调试
安装好摄像头后,为了测试摄像头能否正常工作,可以用一下软件。比较著名的是xawtv,在网上搜以下可以下载到。安装好后,打开xawtv则可以调试摄像头。
3. Video4Linux 编程获取数据。
现有的video4linux有两个版本,v4l和v4l2。本文主要是关于v4l的编程。利用v4l API获取视频图像一般有以下几步:
a> 打开设备
b> 设置设备的属性,比如图像的亮度,对比度等等
c> 设定传输格式和传输方式
d> 开始传输数据,一般是一个循环,用以连续的传输数据
e> 关闭设备
下面具体介绍v4l编程的过程。首先指出,在video4linux编程时要包含
1)v4l的数据结构
在video4linux API中定义了如下数据结构,详细的数据结构定义可以参考v4l API的文档,这里就编程中经常使用的数据结构作出说明。
首先我们定义一个描述设备的数据结构,它包含了v4l中定义的所有数据结构:
typedef struct _v4ldevice
{
int fd; //设备号
struct video_capability capability;
struct video_channel channel[10];
struct video_picture picture;
struct video_clip clip;
struct video_window window;
struct video_capture capture;
struct video_buffer buffer;
struct video_mmap mmap;
struct video_mbuf mbuf;
struct video_unit unit;
unsigned char *map; //mmap方式获取数据时,数据的首地址
pthread_mutex_t mutex;
int frame;
int framestat[2];
int overlay;
}v4ldevice;
下面解释上面这个数据结构中包含的数据结构,这些结构的定义都在
* struct video_capability
name[32] Canonical name for this interface
type Type of interface
channels Number of radio/tv channels if appropriate
audios Number of audio devices if appropriate
maxwidth Maximum capture width in pixels
maxheight Maximum capture height in pixels
minwidth Minimum capture width in pixels
minheight Minimum capture height in pixels
这一个数据结构是包含了摄像头的属性,name是摄像头的名字,maxwidth maxheight是摄像头所能获取的最大图像大小,用橡素作单位。
在程序中,通过ioctl函数的VIDIOCGCAP控制命令读写设备通道已获取这个结构,有关ioctl的使用,比较复杂,这里就不说了。下面列出获取这一数据结构的代码:
int v4lgetcapability(v4ldevice *vd)
{
if(ioctl(vd->fd, VIDIOCGCAP, &(vd->capability)) < 0) {
v4lperror("v4lopen:VIDIOCGCAP");
return -1;
}
return 0;
}
* struct video_picture
brightness Picture brightness
hue Picture hue (colour only)
colour Picture colour (colour only)
contrast Picture contrast
whiteness The whiteness (greyscale only)
depth The capture depth (may need to match the frame buffer depth)
palette Reports the palette that should be used for this image
这个数据结构主要定义了图像的属性,诸如亮度,对比度,等等。这一结构的获取通过ioctl发出VIDIOCGPICT控制命令获取。
* struct video_mbuf
size The number of bytes to map
frames The number of frames
offsets The offset of each frame
这个数据结构在用mmap方式获取数据时很重要:
size表示图像的大小,如果是640*480的彩色图像,size=640*480*3
frames表示帧数
offsets表示每一帧在内存中的偏移地址,通过这个值可以得到数据在图像中的地址。
得到这个结构的数据可以用ioctl的VIDIOCGMBUF命令。源码如下:
int v4lgetmbuf(v4ldevice *vd)
{
if(ioctl(vd->fd, VIDIOCGMBUF, &(vd->mbuf))<0) {
v4lperror("v4lgetmbuf:VIDIOCGMBUF");
return -1;
}
return 0;
}
而数据的地址可以有以下方式计算:
unsigned char *v4lgetaddress(v4ldevice *vd)
{
return (vd->map + vd->mbuf.offsets[vd->frame]);
}
2)获取影像mmap方式。
在video4linux下获取影像有两种方式:overlay和mmap。由于我的摄像头不支持overlay方式,所以这里只谈mmap方式。
mmap方式是通过内存映射的方式获取数据,系统调用ioctl的VIDIOCMCAPTURE后,将图像映射到内存中,
然后可以通过前面的v4lgetmbuf(vd)函数和v4lgetaddress(vd)函数获得数据的首地址,这是李可以选择是将它显示出来还是放到别的什么地方。
下面给出获取连续影像的最简单的方法(为了简化,将一些可去掉的属性操作都去掉了):
char* devicename="/dev/video0";
char* buffer;
v4ldevice device;
int width = 640;
int height = 480;
int frame = 0;
v4lopen("/dev/video0",&device); //打开设备
v4lgrabinit(&device,width,height); //初始化设备,定义获取的影像的大小
v4lmmap(&device); //内存映射
v4lgrabstart(&device,frame); //开始获取影像
while(1){
v4lsync(&device,frame); //等待传完一帧
frame = (frame+1)%2; //下一帧的frame
v4lcapture(&device,frame); //获取下一帧
buffer = (char*)v4lgetaddress(&device);//得到这一帧的地址
//buffer给出了图像的首地址,你可以选择将图像显示或保存......
//图像的大小为 width*height*3
..........................
}
为了更好的理解源码,这里给出里面的函数的实现,这里为了简化,将所有的出错处理都去掉了。
int v4lopen(char *name, v4ldevice *vd)
{
int i;
if((vd->fd = open(name,O_RDWR)) < 0) {
return -1;
}
if(v4lgetcapability(vd))
return -1;
}
int v4lgrabinit(v4ldevice *vd, int width, int height)
{
vd->mmap.width = width;
vd->mmap.height = height;
vd->mmap.format = vd->picture.palette;
vd->frame = 0;
vd->framestat[0] = 0;
vd->framestat[1] = 0;
return 0;
}
int v4lmmap(v4ldevice *vd)
{
if(v4lgetmbuf(vd)<0)
return -1;
if((vd->map = mmap(0, vd->mbuf.size, PROT_READ|PROT_WRITE, MAP_SHARED, vd->fd, 0)) < 0) {
return -1;
}
return 0;
}
int v4lgrabstart(v4ldevice *vd, int frame)
{
vd->mmap.frame = frame;
if(ioctl(vd->fd, VIDIOCMCAPTURE, &(vd->mmap)) < 0) {
return -1;
}
vd->framestat[frame] = 1;
return 0;
}
int v4lsync(v4ldevice *vd, int frame)
{
if(ioctl(vd->fd, VIDIOCSYNC, &frame) < 0) {
return -1;
}
vd->framestat[frame] = 0;
return 0;
}
int c4lcapture(v4ldevice *vd, int frame)
{
vd->mmap.frame = frame;
if(ioctl(vd->fd, VIDIOCMCAPTURE, &(vd->mmap)) < 0) {
return -1;
}
vd->framestat[frame] = 1;
return 0;
}
Linux动态链接库的创建与使用
本文主要探讨Linux下动态链接库的创建与使用。
一. 创建
下面举一个例子:
/*
add.h
*/
#ifndef _ADD_H
#define _ADD_H
#ifdef SHARED
int (* addnum)(int a, int b);
#endif
#endif
/*
addnum.c
*/
#include "add.h"
#include
int addnum(int a,int b){
int c=a+b;
return c;
}
然后用gcc将这两个文件编译成动态链接库.so文件。
gcc -c add.h addnum.c
gcc -shared -o addnum.so addnum.o
这样就生成了动态链接库addnum.so文件
二. 使用动态链接库
/* main.c */
#include
#include
#define SOFILE "./addnum.so"
#define SHARED
int main(){
printf("Open Dynamic Lib!\n");
void *dp=dlopen(SOFILE,RTLD_LAZY);
int (*addnum)(int,int);
if(NULL==dp){
printf("Open Dynamic Lib Failed!\n");
return -1;
}
addnum=dlsym(dp,"addnum");
int a=10,b=20;
int c=addnum(a,b);
printf("The sum is : %d\n",c);
dlclose(dp);
return 1;
}
用如下的命令编译:
gcc main.c -ldl -o main
然后运行:
./main
结果是:
The Sum is :30
但是,如果定义成C++文件,上述方法在使用时可能会出问题,此时需要强制类型转换.
addnum=(int (*)(int,int))dlsym(dp,"addnum")
Natural Image Matting
Introduction
Composition Image I is generated by foreground and background with alpha matte
I = alpha*F + (1-alpha)*B
Matting is a problem to get alpha,F,B from a given image I.
User have to devide the image into three region: Foreground, Background and Unknown area. In foreground area, F = I, alpha = 1, B = 0; In background area, F = 0, alpha = 0, B = I. Our task is to get F,B,alpha in unknown area.
Consider a point P in unknown area, we have to first estimate F and B in point P.
After estimate F,B in point P, we estimate alpha by minimize a energy:
V = a*V(P) + b*V(P,Q) Q is 4-neighbor of P
V(P) = C - alpha*F - (1-alpha)*B^2
V(P,Q) = alpha(P) - alpha(Q)^2
Result


Reference (All can be downloaded from Google)
- Y.Chuang, B.Curless, DH.Salesin, R.Szeliski, A Bayesian Approcah to Digital Matting.
- J.Sun, J.Jia, CK.Tang, HY.Shum, Poisson Matting.
- A.Levin, D.Lischinski, Y.Weiss, A Closed Form Solution to Natural Image Matting.
- J.Wang, MF.Cohen, An Iterative Optimization for Unified Image Segmentation and Matting.
Progressive Mesh Algorithm based on HalfEdge Mesh Structure
这是我的本科毕业论文,嘿嘿!
Abstract:
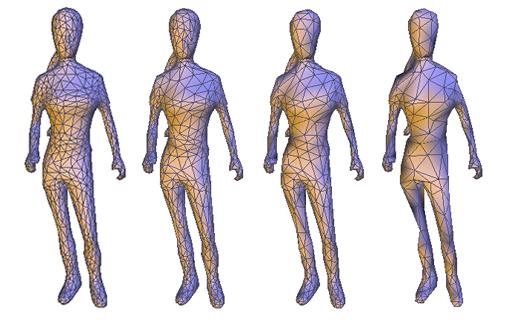
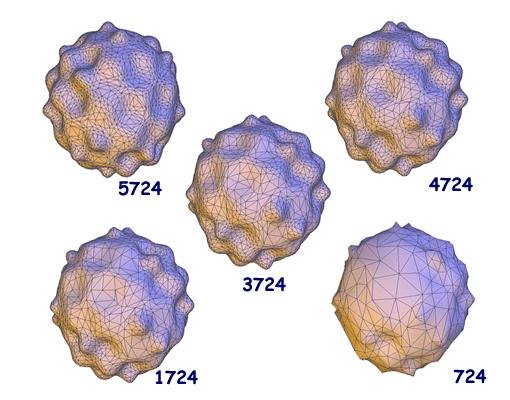
When storing, rendering, transmitting highly detailed mesh models, we may meet difficulty like slow speed or poor quality. In order to solve these problems, Hoppe introduced Progressive Mesh(PM) Representation, and this method has broad application in Mesh Simplification, Level-of-detail, Progressive Transmission, Mesh Compression, and so on. In this thesis, I realize PM algorithm in HalfEdge Mesh structure. Compared with general mesh structure, halfedge structure can improve many algorithms' arithmetic speed, and it's easy to obtain mesh topological structure by using halfedge mesh structure. This thesis consists of five parts. First, the background of PM will be given. Next, an interactive computer graphics platform which supports rotation, scaling, translation, selection will be introduced. 3D objects' mesh representation will be discussed in third part. In the fourth part, PM algorithm will be explained in detail. Discussion is the final of this thesis.
Result:
These are a part of results of undergraduate thesis, mainly use Progressive Mesh Algorithm to do Mesh Simplification.

Abstract:
When storing, rendering, transmitting highly detailed mesh models, we may meet difficulty like slow speed or poor quality. In order to solve these problems, Hoppe introduced Progressive Mesh(PM) Representation, and this method has broad application in Mesh Simplification, Level-of-detail, Progressive Transmission, Mesh Compression, and so on. In this thesis, I realize PM algorithm in HalfEdge Mesh structure. Compared with general mesh structure, halfedge structure can improve many algorithms' arithmetic speed, and it's easy to obtain mesh topological structure by using halfedge mesh structure. This thesis consists of five parts. First, the background of PM will be given. Next, an interactive computer graphics platform which supports rotation, scaling, translation, selection will be introduced. 3D objects' mesh representation will be discussed in third part. In the fourth part, PM algorithm will be explained in detail. Discussion is the final of this thesis.
Result:
These are a part of results of undergraduate thesis, mainly use Progressive Mesh Algorithm to do Mesh Simplification.
订阅:
博文 (Atom)
